At work, I’ve recently been splitting our many of our services into their own repo, migrating from a Monorepo-style architecture towards an eventual Multirepo-style future.
Since my .dotfiles repo is was a Mono, I wanted to take some time to highlight the differences between the types of repos, how to configure automatic deployments, and the various challenges between each.
Overview and Goals
This first section will highlight why someone might want to use a Multirepo rather than a Monorepo. I’ll highlight the use case at work compared to my personal experience with the .dotfiles repo and how each makes sense.
In addition, we’ll examine how the developer experience is almost identical for both, despite the differences in repository management.
Comparing Monorepo vs. Multirepo
Both of these terms are used to compare methods of version-control systems, with a Monorepo housing multiple different projects or applications and a Multirepo splitting independent pieces of code into their on VCS.
Monorepos were first popularized in the early 2000s by tech giants like Google and Microsoft, though recently the standard has shifted towards the Multirepo approach. Neither is perfect, though the shift (in my opinion) is largely driven by the more explicit dependency management and more lightweight management of individual Multirepos.
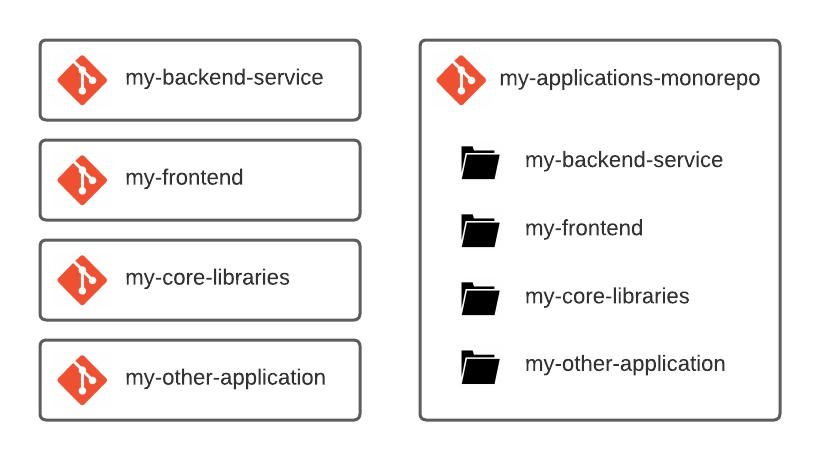 Monorepos contain multiple projects which are otherwise split in a Multirepo setup.
Monorepos contain multiple projects which are otherwise split in a Multirepo setup.
A Monorepo is also slightly different from a Monolithic application, which combines each sub-application into one large project. Monorepos can have multiple independent artifacts, they just live under a single version control.
Dependency Management
Since Monorepos (often) use only one version of any dependency, builds can be easily optimized around the single version in the codebase. However, this can sometimes be a challenge if breaking changes to an external library affect only part of the codebase. An upgrade can also be limited if any code can’t use the latest version, even if other applications are unaffected.
By contrast, Multirepos can each use separate versions of their third-party libraries, though this can bloat builds if each application needs to download its own version of a dependency. Upgrades can take longer, though, since each individual repo will need its dependencies to be updated.
Code Reuse / Large-Scale Refactoring
Monorepos can take advantage of common libraries being easily shared across all sub-projects. It’s also simpler to refactor these libraries, as changes must propagate across the entire repo in order for the refactor to take effect.
The downside is that refactors must sweep across the entire codebase to take effect, while Multirepos can often continue to use old versions of shared libraries in order to continue using not-yet-refactored code.
However, the development process for refactors in Multirepos often takes more time, since they must wait for refactor changes to be published from the common library before they can start upgrading their existing users.
Version Information
Many Monorepos use a single version across all projects. This is often required due to semantic differences updating a Monorepo compared to a Multirepo. For example, a refactoring to a common library will update all users across the codebase, so in theory the entire Monorepo has been updated.
Within a Multirepo, the common library would be refactored and update it’s version, and then dependent libraries can update their versions as they use the latest version of the common library.
Per-project versions can provide extra value to users, especially with Semantic Versioning (discussed more below). Though this can be lost within a Monorepo if steps are not taken to version sub-modules independently.
Collaboration Across Teams
Monorepos enable any teammate to modify any piece of code. That flexible code ownership also means teams can improve code “owned” by other teams.
However, a Monorepo also prevents anyone from getting restricted access to the repo. It’s all or nothing, which isn’t ideal in a codebase with hundreds or thousands of developers.
A Monorepo also means developers will need to download the entire codebase, even if they want to make a small, targeted change. When running continuous integration / deployment pipelines, this can also increase build times since all dependencies need to be re-built and re-tested, even for just a minor change in a single application.
Intended Experience
Ideally, users of our repos should follow this workflow:
- Developer pushes code in a feature branch to the repo and opens a pull request.
- A CI/CD pipeline is started to verify tests and ensure the code is ready for committal to
main. - Developer receives approval from a teammate, their build passes, and they merge their branch.
- Another pipeline is started on
mainto publish those changes:- Tooling marks it as a stable release, and makes a commit to
gitwith a matching tag. - Latest version of the code is compiled into deployable components.
- Build artifacts are published to corresponding environments
- Tooling marks it as a stable release, and makes a commit to
- Developer deploys the changes, if manual intervention is needed, or it can otherwise be automatically be deployed.
Semantic Versioning
Semantic versioning is a strategy for assigning version numbers to builds of software in such a way that they can properly carry meaning — specifically, meaning about how the code changes between versions.
While versions are by design strictly ordered (and therefore can be used as a simple sequential version number) they’re most useful for controlling interactions between components by defining changes as belonging to one of three categories: major, breaking changes; minor, feature adds; and patches or bugfixes.
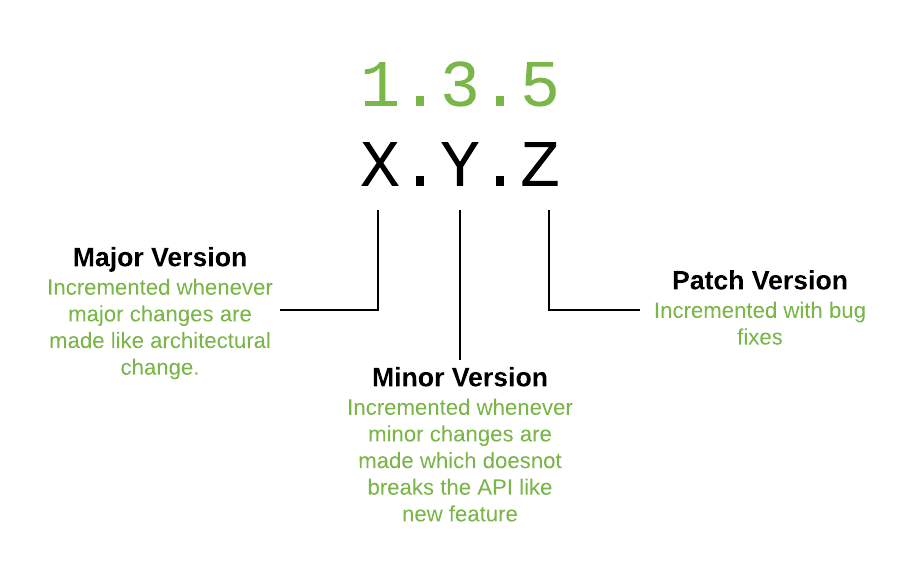 The three number values used within Semantic Versioning. Image courtesy of devopedia.org
The three number values used within Semantic Versioning. Image courtesy of devopedia.org
{kind=link}
“Official” documentation is present at semver.org, though usage may differ as the standard is a well-defined set of guidelines more than an explicit set of rules.
Version Number Components
Semantic Version numbers (as a baseline) contain three values, separated by dots. For example, a valid Semantic Version is 2.14.1. The first value (in this case, 2) is the “major” version number, the second (14) is the “minor” version, and the final (1) is the “patch” version.
Some versions may contain additional information in a suffix, such as a git commit, though the idea is that the intended code version is the same.
How to Split Out a Maven Package
Migrating an existing Maven package from a Monorepo to a Multirepo can be an arduous process. This section aims to outline a few helpful steps that can simplify the process as well as some concepts about Maven that I learned when doing migrations myself.
Generating an Effective POM
Maven can generate the initial dependencies for a given package into a POM for you! This can be a great starting point rather than copy-pasting the existing pom.xml — which likely has more dependencies than you need — or starting from scratch.
From IntelliJ, open the context menu (right click, Cmd + click, two-finger click, etc.) for the package you want, then navigate to
Maven > Show Effective POM.
Alternatively, if you aren’t using IntelliJ, you can create an effective POM using the :effective-pom command. More about it here.
Now you can copy that file to use as the starting pom.xml for the split-off package.
Understanding How SNAPSHOTs Work
The SNAPSHOT suffix on a build version indicates that any built code is unstable and could change as the latest version is developed. The suffix is appended to the Semantic Version to provide extra context to any users.
During a release, the SNAPSHOT suffix is removed (e.g. 2.14.1-SNAPSHOT becomes 2.14.1) and then the POM is amended to bump up to a SNAPSHOT release of the next version (e.g. 2.14.2-SNAPSHOT).
For more information, Apache has a guide to how SNAPSHOTs work here.
Connecting to BitBucket
There’s an scm (software configuration management) section in the POM that let’s us connect to git for specific operations. This is needed within the BitBucket Pipelines to push out commits or tags with new versions of the code. Yours should look something like this:
<scm>
<developerConnection>
scm:git:ssh://git@github.com/cwboden/.dotfiles.git
</developerConnection>
<tag>dotfiles-1.0.0</tag>
</scm>The contents of developerConnection should (mostly) match the ssh URI you get when cloning the repo; just make sure to add the scm: prefix!
Starting Pipelines from PRs
BitBucket won’t let you start running Pipelines until you have a bitbucket-pipelines.yml file in the root of the repository. Since you’ll want to test the Pipeline changes before committing them, it can be useful to have a blank template committed so that pull requests can kick off a Pipeline build.
From the home page of your repository, navigate to
Repository Settings > PIPELINES > Settingsand follow the instructions to enable Pipelines. BitBucket may help you create a blank template, or you can use a copy from another repo.
Now, Pipelines should be enabled and can be run on future pull requests. It’s worth noting that Pipelines will use the PR’s version of bitbucket-pipelines.yml and you can run any version of a Pipeline using the Run Pipeline button on the Pipelines page of the repo.
For guidance on what a configuration should look like, their starter guide is nice for building context. You can then look at the bitbucket-pipeline.yml files in other repos (or even the GitHub Pipelines file in this repo) for a good starting point.
Avoiding a Build/Deploy Infinite Loop
The way Pipelines are configured, we start one on main anytime a new commit is made. This works great when we merge in PRs, but since the maven-release plugin makes commits whenever we run the Pipeline to update the package’s version, you can imagine how that can be a problem.
By adding [skip ci] at the start of those commits, we can ensure this doesn’t happen. Add these lines to the maven-release-plugin section of your POM:
<plugin>
<artifactId>maven-release-plugin</artifactId>
<version>2.5.3</version>
<configuration>
<!-- Skip JavaDoc processing, since it doesn't support Kotlin code. -->
<arguments>-Dmaven.javadoc.skip=true</arguments>
<scmCommentPrefix>[skip ci] [maven]</scmCommentPrefix>
</configuration>
</plugin>Optionally, you may want to add the javadoc disable option if your code is having issues building the docs during deployment. If your repo has both Java and Kotlin, this is likely the case.
How Builds are Configured within .dotfiles
My personal repo (this one, .dotfiles) has a similar developer experience where merged PRs are immediately deployed to the website after passing a GitHub pipeline. However, as a Monorepo, there are some differences in why and how it’s configured.
Using a Monorepo for Personal Development
Since this repo is for my personal projects (and blog), I don’t need many of the advantages of a Multirepo:
As the only one touching the code, I don’t have a need to version it, since there aren’t any consumers. I also don’t need to limit access between developers, and a Monorepo ensures my wide-sweeping refactors and changes propagate across the entire codebase.
And while it would be good practice to split some of my projects into their own repo, I’d rather save the time I would be spending maintaining the infrastructure for each repo:
For example, I use git pre-commit hooks to apply style rules, formatting, and security checks whenever committing code. It would be expensive to update those hooks for every single repo whenever I made a change. As a result, I’ve kept everything important in a Monorepo for easy access.
Limiting Scope during Build / Test
To help pare down build and test times, I’ve taken advantage of the dorny/paths-filter Workflow action to determine which files have changed. This snippet highlights the important parts:
detect-changes:
runs-on: ubuntu-latest
outputs:
bootstrap: ${{ steps.filter.outputs.bootstrap }}
python: ${{ steps.filter.outputs.python }}
rust: ${{ steps.filter.outputs.rust }}
website: ${{ steps.filter.outputs.website }}
steps:
- uses: dorny/paths-filter@v2
id: filter
with:
filters: |
...
python:
- '*.py'
...
...
python:
needs: detect-changes
if: ${{ needs.detect-changes.outputs.python == 'true' }}
...The outputs section defines variables that can be compared by future steps. In the above example, we check if the python output is true before running the python build and test Workflow. There are similar definitions for each other “application” I have in this repo: bootstrap, rust, and website.
Then, within filters, we define how to check for changes from git. For the python output we just see if any *.py files have changed, though we could limit this more explicitly if we want to check for changes within a specific directory or project.
As a result, GitHub will only run specific Workflows if changes are actually present. No point running our test suite on a project that hasn’t changed! (Though be aware of transitive dependencies that won’t be covered by this approach.)
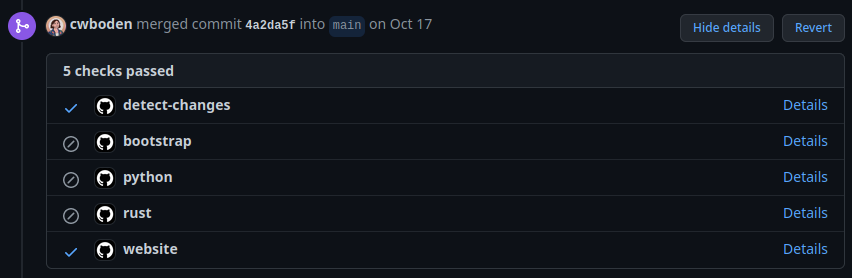
In theory, this Workflow could be expanded to update versions of changed packages accordingly, though I haven’t had a use for versioning just yet.
For more details about how to use GitHub Workflows, see their documentation.